GSoC — The Work So Far
In this blog post, I will discuss the work I have done so far, and what our future direction will be.
Fast 5×5
In 2019, Hadrien worked with a Masters student to create Fast 5×5, which was supposed to be a proof-of-concept demonstrating that the existing matrix routines in Eigen could be better optimized for small dimensions like 5×5.
My Changes to Fast 5×5
The first thing my mentors recommended doing was to take a closer look at the repository and understand where we stand with respect to the work to be done.
After looking at fast5x5.hpp for a while, I decided that I should make some changes to make the benchmarking program faster and more reliable. So, I started making changes to the repository. I started off by removing the Docker stuff because it would not be necessary for the project.
After making a few changes, it became apparent that I needed somewhere to push my changes to, so that it was available for everyone to see and use. However, because the original project was on GitLab, I could not fork it the way projects on GitHub can be forked. Instead, I pushed my copy of the GitLab repository onto GitHub, and made sure to point to the original URL in my repository description. The original repository can be found here, and my fork can be found here.
Repository Reorganization
The original directory structure was quite flat. However, it was not amenable to the amount and volume of changes I needed to make. For this reason, I reorganized the entire repository multiple times (for example, in 85ad3fd, 20d4fb9, 125a084, and 69bd4d8).
The original directory structure was:
.
├── README.md
├── CMakeLists.txt
├── custom_scal.txt
├── eigen_scal.txt
├── analysis.R
├── measure_perf.sh
├── fast5x5.hpp
├── matrix_product_custom.cpp
├── matrix_product_eigen.cpp
├── benchmark/
│ ├── benchmark.sh
│ ├── gemm_custom.cpp
│ ├── gemm_eigen.cpp
│ ├── gemm_header.h
│ └── gemm_simple.cpp
├── docker/
│ ├── Dockerfile-extracts
│ ├── kokkos
│ └── xsimd
└── test/
├── CMakeLists.txt
├── unit_inverse.cpp
├── unit_matrix.cpp
├── unit_operator.cpp
├── unit_vector.cpp
└── run_all.cppThe current (at the time of writing) file structure is as follows:
.
├── README.md
├── CMakeLists.txt
├── include/
│ ├── fast5x5/
│ │ └── fast5x5.hpp
│ └── benchmarks/
│ ├── coord-transform
│ ├── gemm
│ ├── inversion
│ ├── similarity
│ ├── shared
│ ├── mat_mul.hpp
│ ├── mat_inv.hpp
│ ├── mat_sim.hpp
│ └── mat_coord_transform.hpp
└── src/
├── CMakeLists.txt
├── libs/
│ ├── eigen
│ ├── xsimd
│ ├── googletest
│ ├── benchmark
│ ├── blaze
│ └── Fastor
├── benchmarks/
│ ├── CMakeLists.txt
│ ├── combined_benchmark.cpp
│ ├── gemm_benchmark.cpp
│ ├── inversion_benchmark.cpp
│ ├── similarity_benchmark.cpp
│ └── coord_transform_benchmark.cpp
└── test/
├── CMakeLists.txt
├── unit_inverse.cpp
├── unit_matrix.cpp
├── unit_operator.cpp
├── unit_vector.cpp
└── run_all.cppThe advantage of the new hierarchical directory structure is that it allows others to get up to speed with respect to where everything is faster, and it also allows me to easily add more benchmarks and backends.
Installed vs. Vendored Libraries
Originally, the repository expected the user to have Eigen and xsimd installed. However, the existing CMakeLists.txt file downloaded Google Test from GitHub, thereby avoiding that library dependency.
In order to minimize library dependencies and make it easier for other people to run the benchmarks, I removed the reliance on user installations and opted to “vendor” the libraries along with the project. Even though both Fast5×5 and algebra-plugins both used CMake to download dependencies from GitHub, I chose the Git submodule approach because I was more familiar with the latter at the time. I added Eigen, xsimd, and GoogleTest as Git submodules. Furthermore, all subsequent additions (like Google Benchmark, blaze, and Fastor) were added as submodules to Fast5×5.
I converted the libraries into submodules in 21aad0e, and then performed an xsimd version upgrade (from v5.0.0 to v7.6.0) in e1e1c71 and performed two Eigen version upgrades in 18dbd4e (from v3.3.4 to v3.4.0), and then in 0e702b0 (from v3.4.0 to 3.4.90).
Due to the fact that I had converted the libraries into submodules, version upgrades were as simple as checking out a new commit in the submodule repository and then committing that change.
/usr/bin/time vs. Google Benchmark
Google Benchmark is a C++ library dedicated to performing micro-benchmarks.
Benchmarking small pieces of code like the ones in this project is called micro-benchmarking. Among software developers, it is well known that micro-benchmarking is tough to do properly because the very nature of the benchmarks means that a small amount of noise (to the order of a few nanoseconds) can greatly alter the results of a specific benchmark.
/usr/bin/time was the original method of benchmarking that was being used. However, it is not well suited to micro-benchmarks because the resolution of the underlying clock used is not that great. On the other hand, Google Benchmark has no problem with reporting the elapsed time for tasks which take a few nanoseconds (5 to 7 ns, for example).
An interesting and very useful feature that Google Benchmark has is its DoNotOptimize() function, which prevents the compiler from optimizing out a certain operation. After all, what good is the benchmark if it isn’t even doing what I am trying to measure? Obviously, /usr/bin/time has no such thing (because it was created for a different purpose), so Google Benchmark is superior in this regard as well.
Apart from these technical considerations, Google Benchmark offers considerable Quality of Life (QoL) features as well, such as the option to run multiple benchmarks back to back, an uniform output format, the option to export the output into different formats like csv and json, and more.
For these reasons, I decided to move away from /usr/bin/time and switched the Google Benchmark instead.
Matrix Generation
A key part of the benchmarking code is the random matrix generation. Doing this properly is essential because otherwise, the compiler might figure out the fact that we have precomputed matrices. Once it does so, it is free to calculate the results ahead of time, which would defeat the point of the benchmark. The original Fast 5×5 code was using index-based operations to fill up the matrix, like so:
float a[SIZE * SIZE];
float b[SIZE * SIZE];
// the BaseMatrix data type in fast5x5.hpp has a constructor
// that takes in C-style arrays. So, the code simply filled
// up two arrays and then made two BaseMatrix objects out
// of them.
for (int i = 0; i < SIZE; i++) {
for (int j = 0; j < SIZE; j++) {
a[i * SIZE + j] = i + j;
}
}
for (int i = 0; i < SIZE; i++) {
for (int j = 0; j < SIZE; j++) {
float val;
if (i == 0 && j == 1) val = -1;
else if (i == 1 && j == 0) val = 1;
else if (i > 1 && i == j && i % 2) val = -1;
else if (i > 1 && i == j && !(i % 2)) val = 1;
else val = 0;
b[i * SIZE + j] = val;
}
}I rewrote the matrix generation code using the random number generators in the <random> header, and mimicked Eigen’s Random() implementation, which generates a random float in the range $[-1, 1]$:
// random.hpp
#include <random>
#include <limits>
inline float randomFloat(float min, float max) {
// Returns a random real in [min, max].
static std::uniform_real_distribution<float> distribution(
min, std::nextafter(max,
std::numeric_limits<float>::infinity()
)
);
static std::mt19937_64 generator;
return distribution(generator);
}
// this is the matrix generation code
float a[SIZE * SIZE];
for (int i = 0; i < SIZE; i++) {
for (int j = 0; j < SIZE; j++) {
a[i * SIZE + j] = randomFloat(-1.0, 1.0);
}
}This change was made in ff821df.
Benchmarking Results
I wrote benchmarks for testing the performance of Eigen, fast5x5, blaze, and Fastor in various matrix computation tasks like matrix multiplication, matrix inversion, computing the similarity transform and computing coordinate transforms in various matrix dimensions (more specifically, in 4×4, 6×6, 6×8, and 8×8).
I ran the benchmarks on my own machine, gathered the data, and then plotted it using a Python script I wrote:
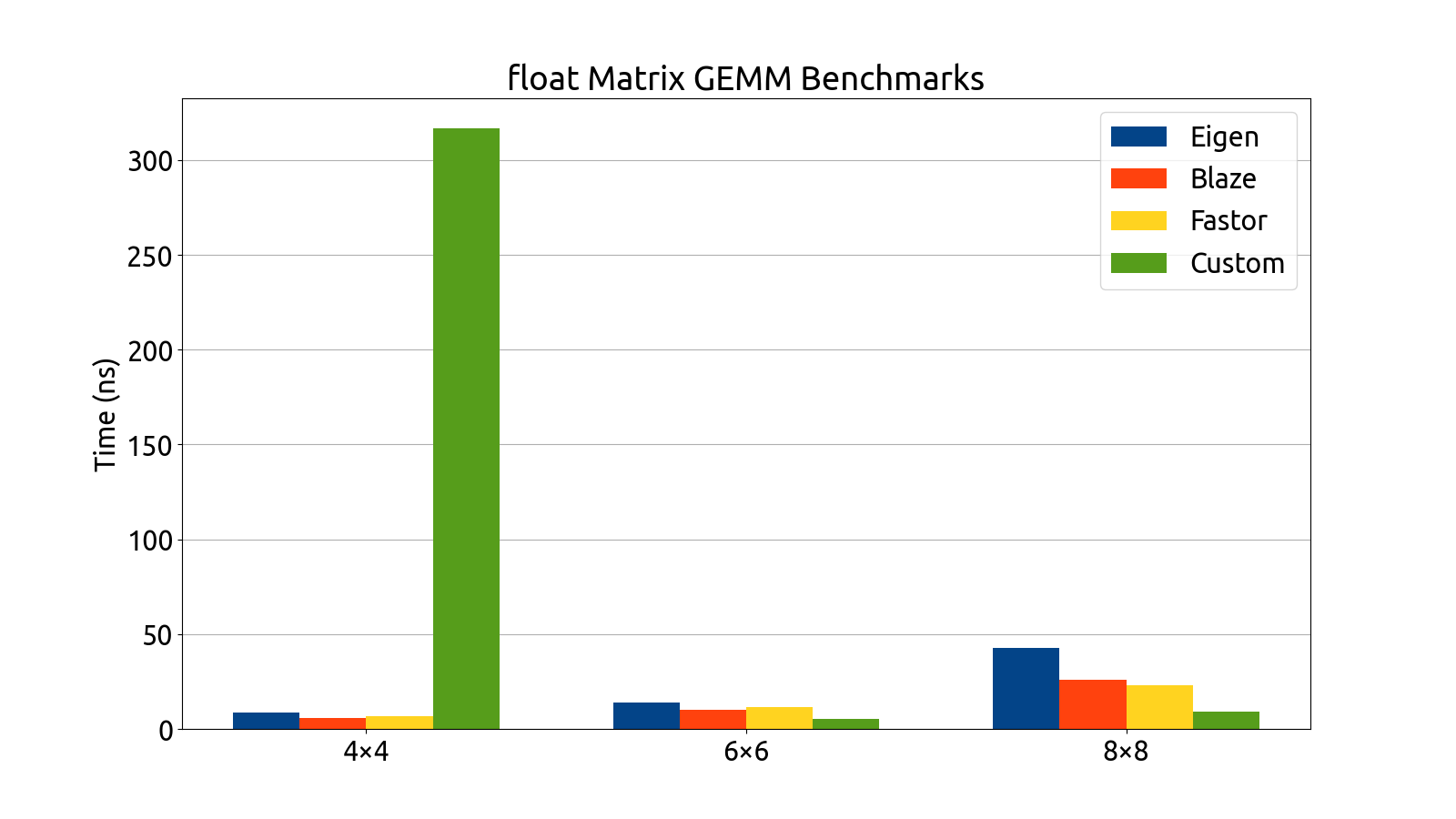
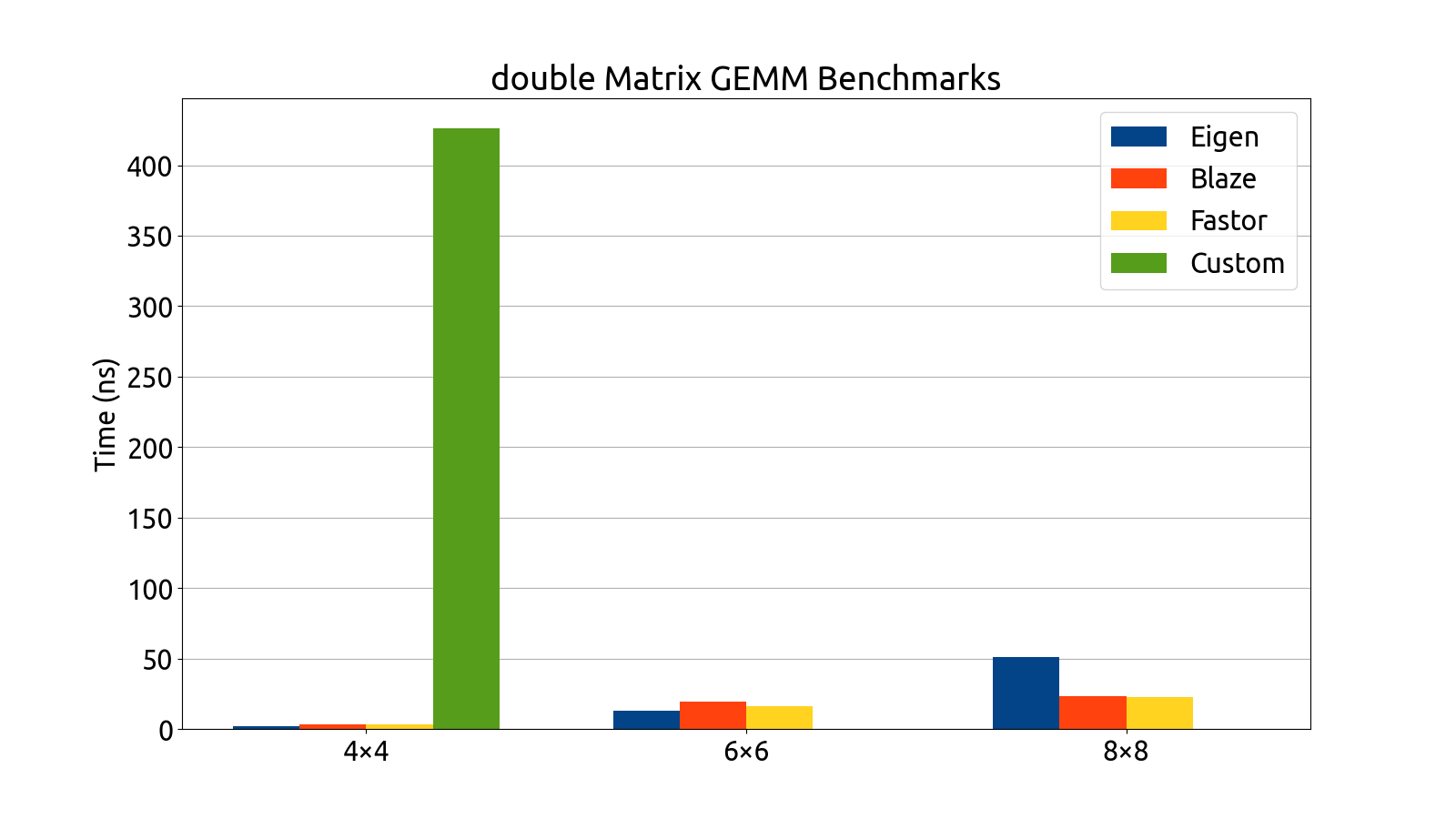
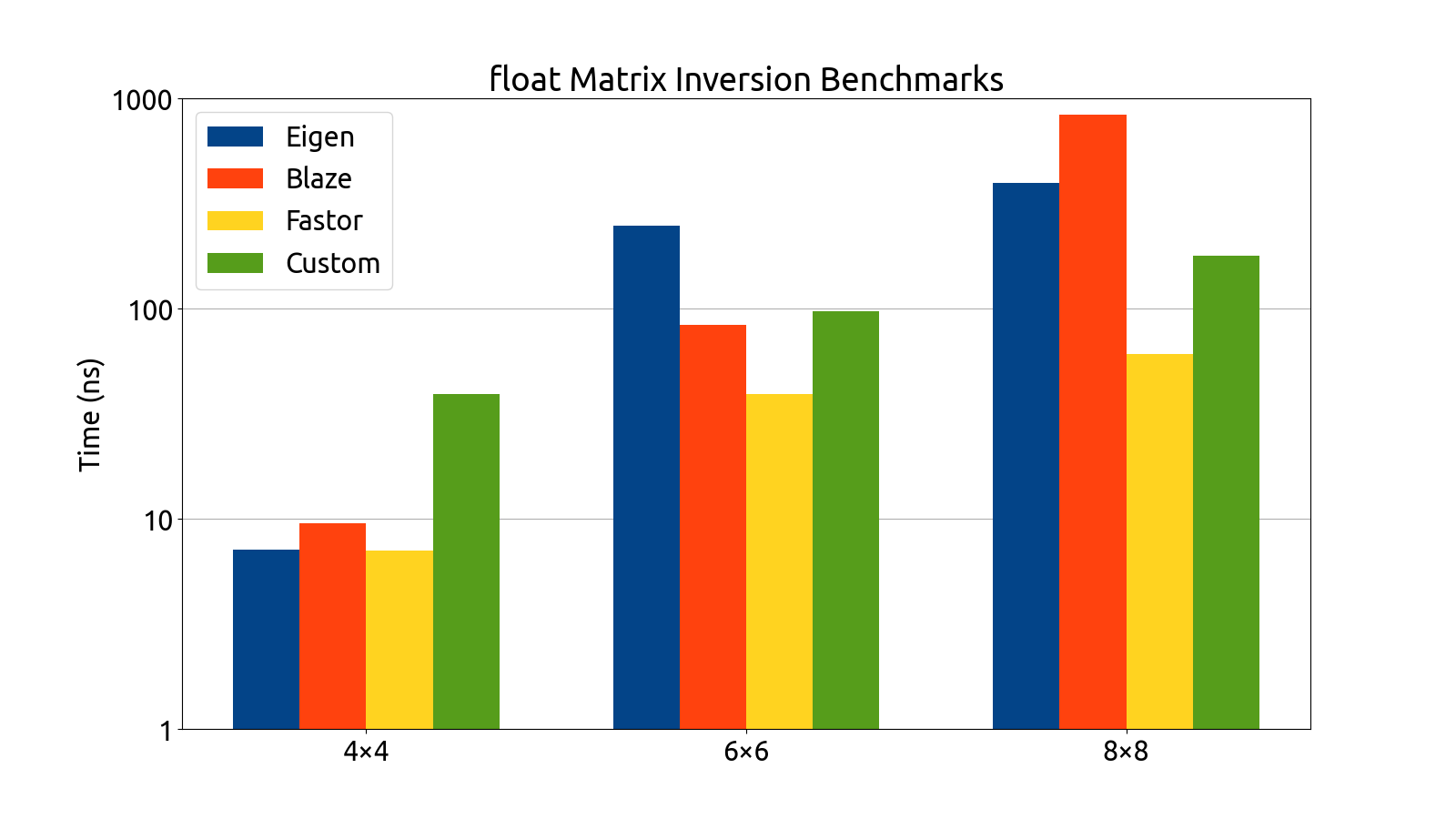
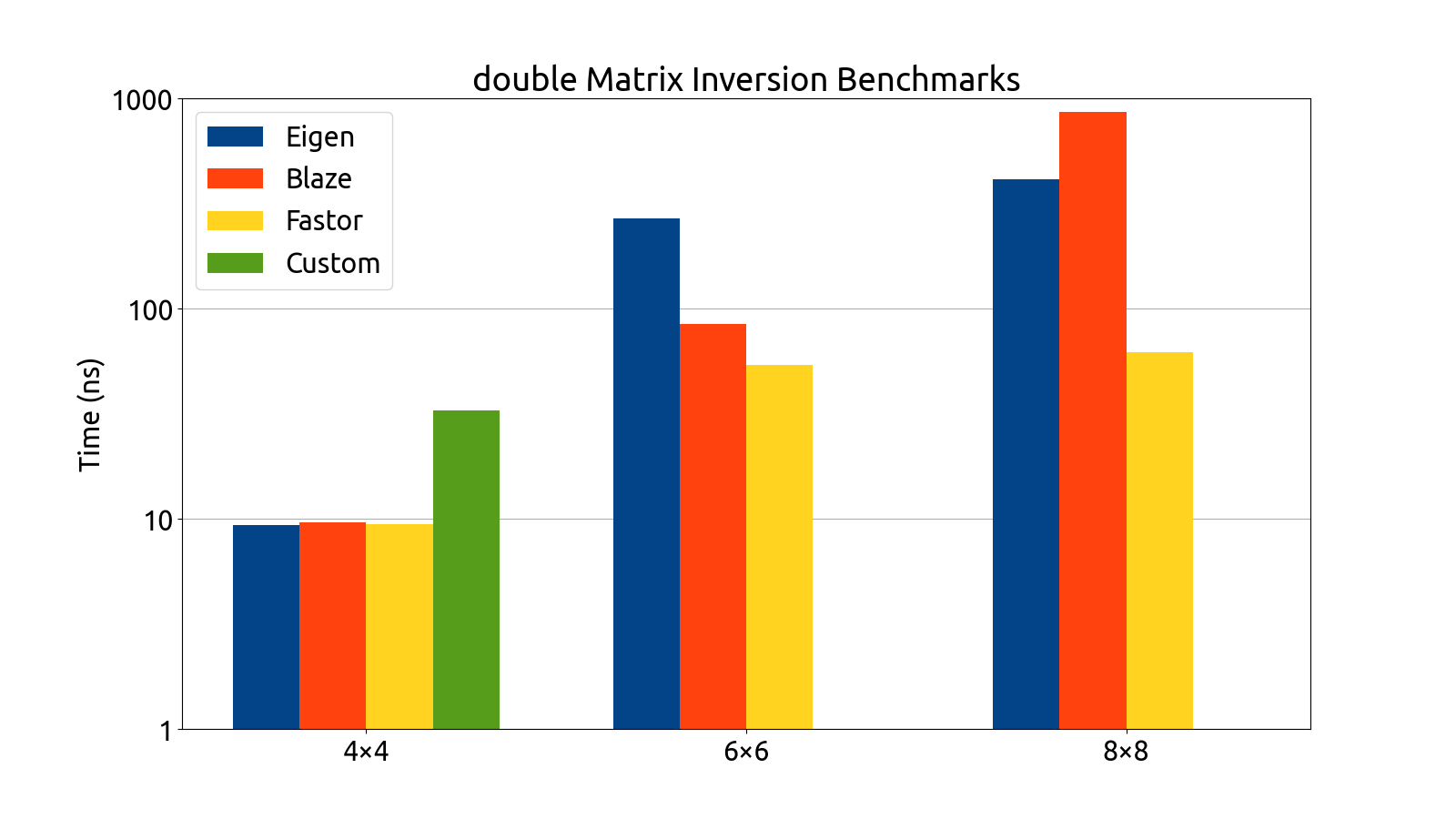
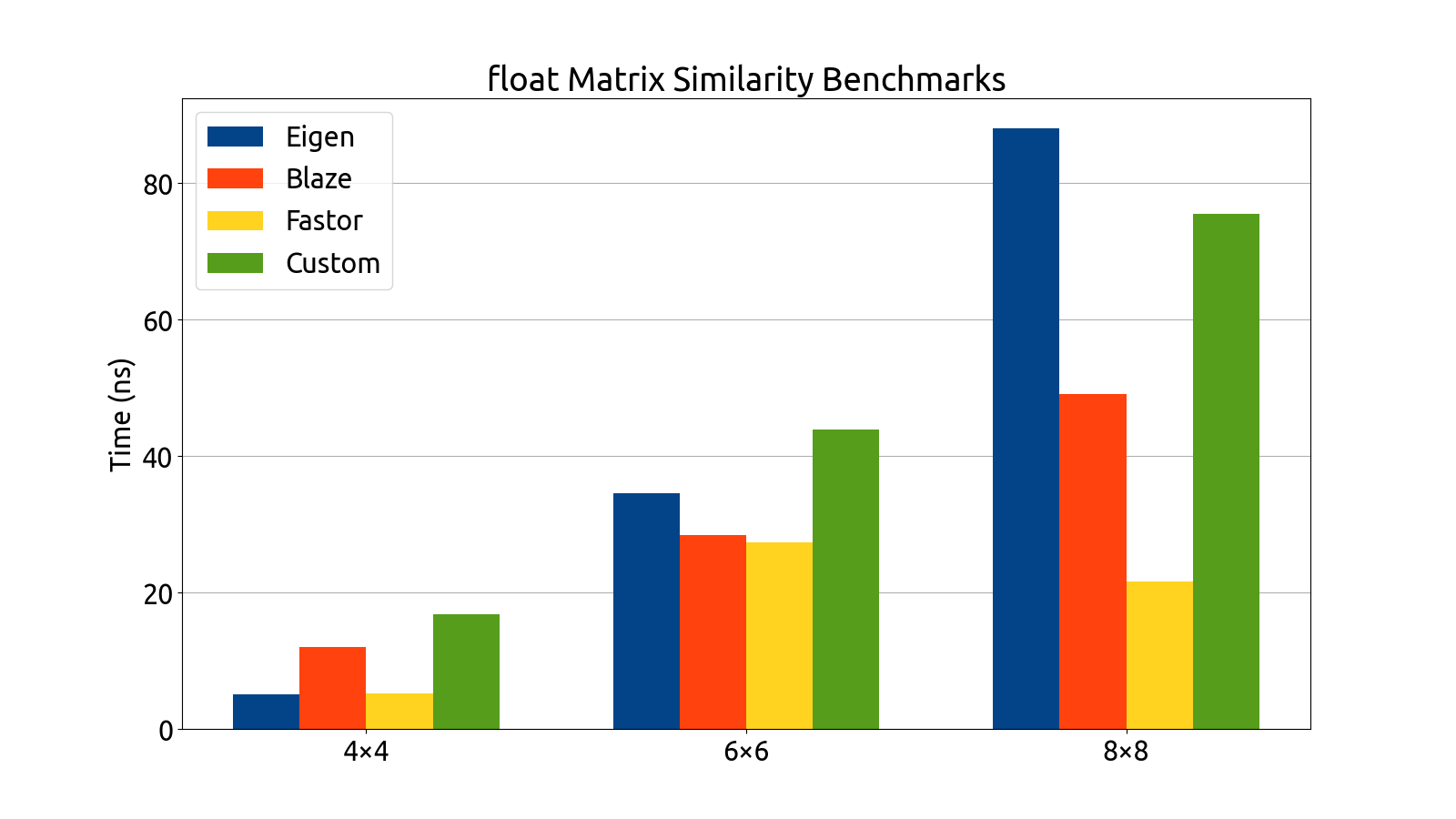
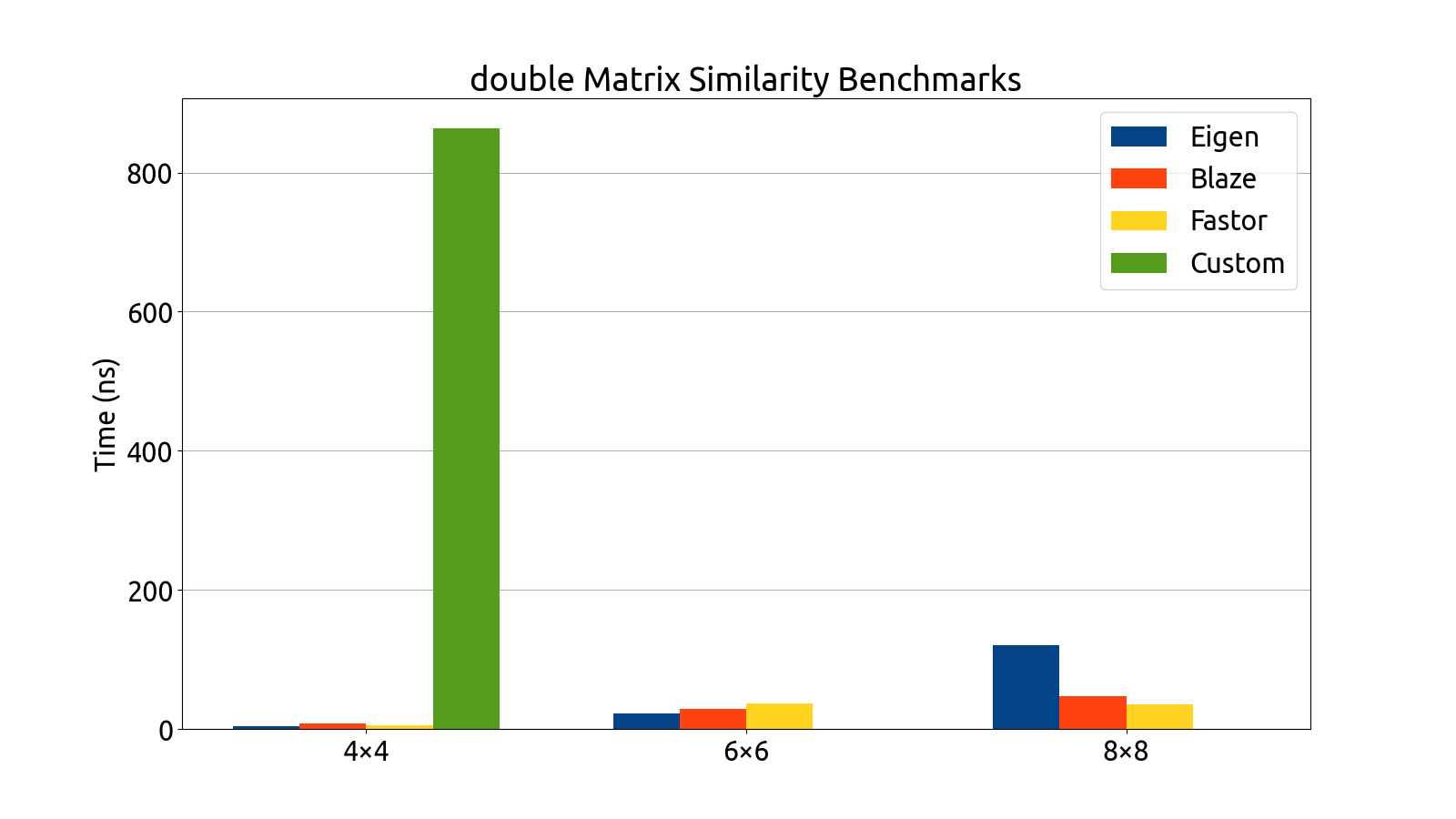
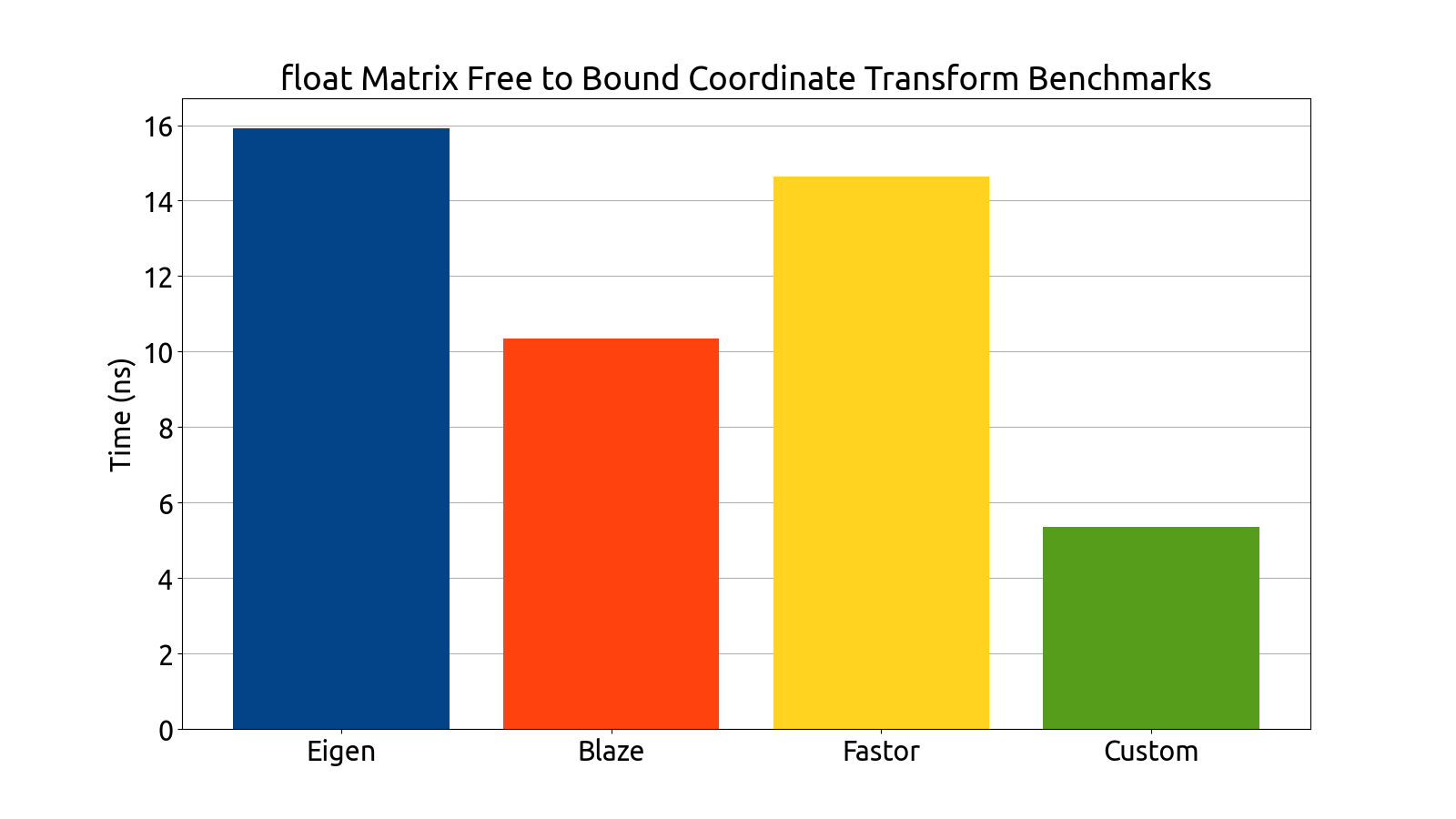
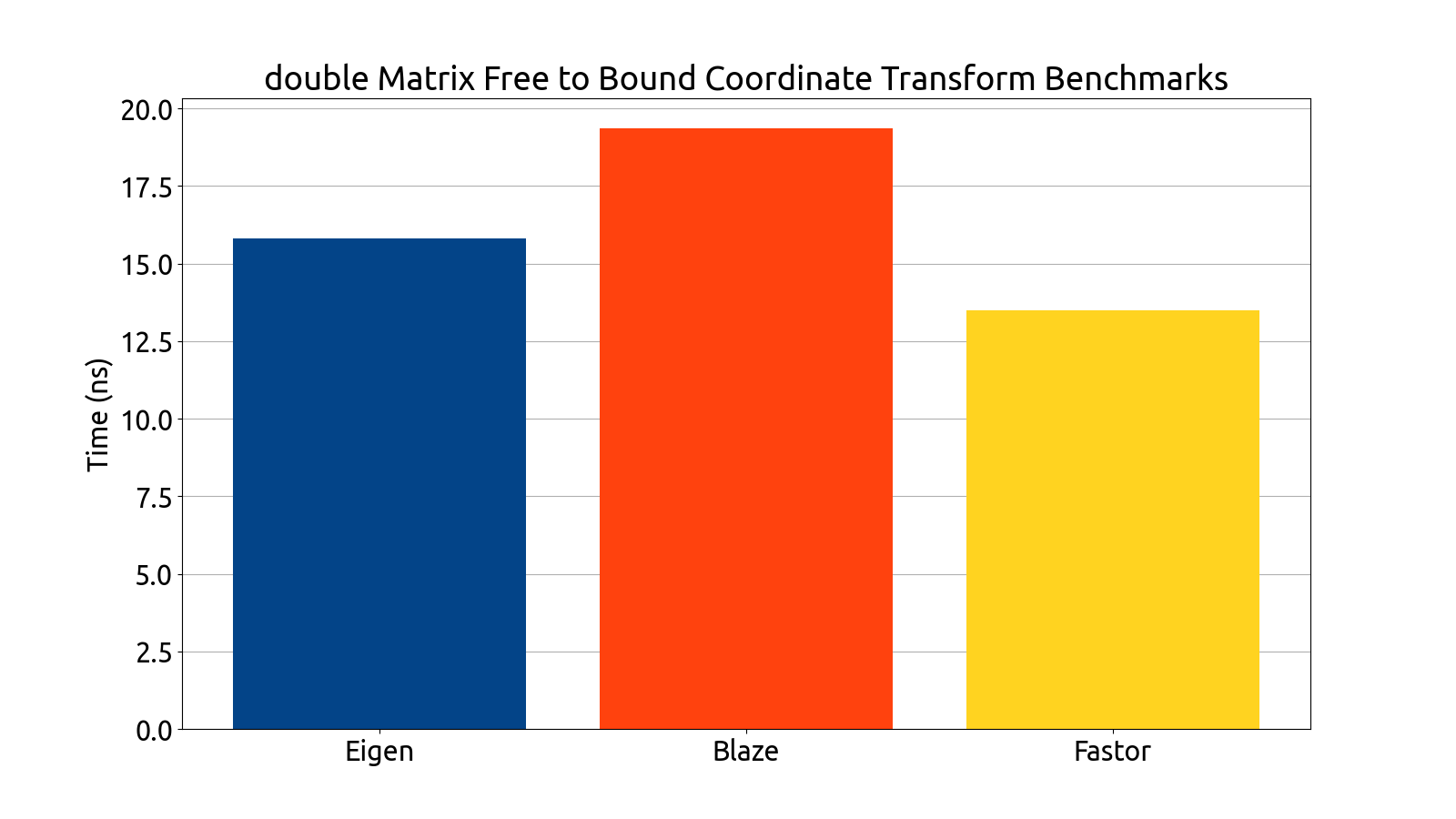
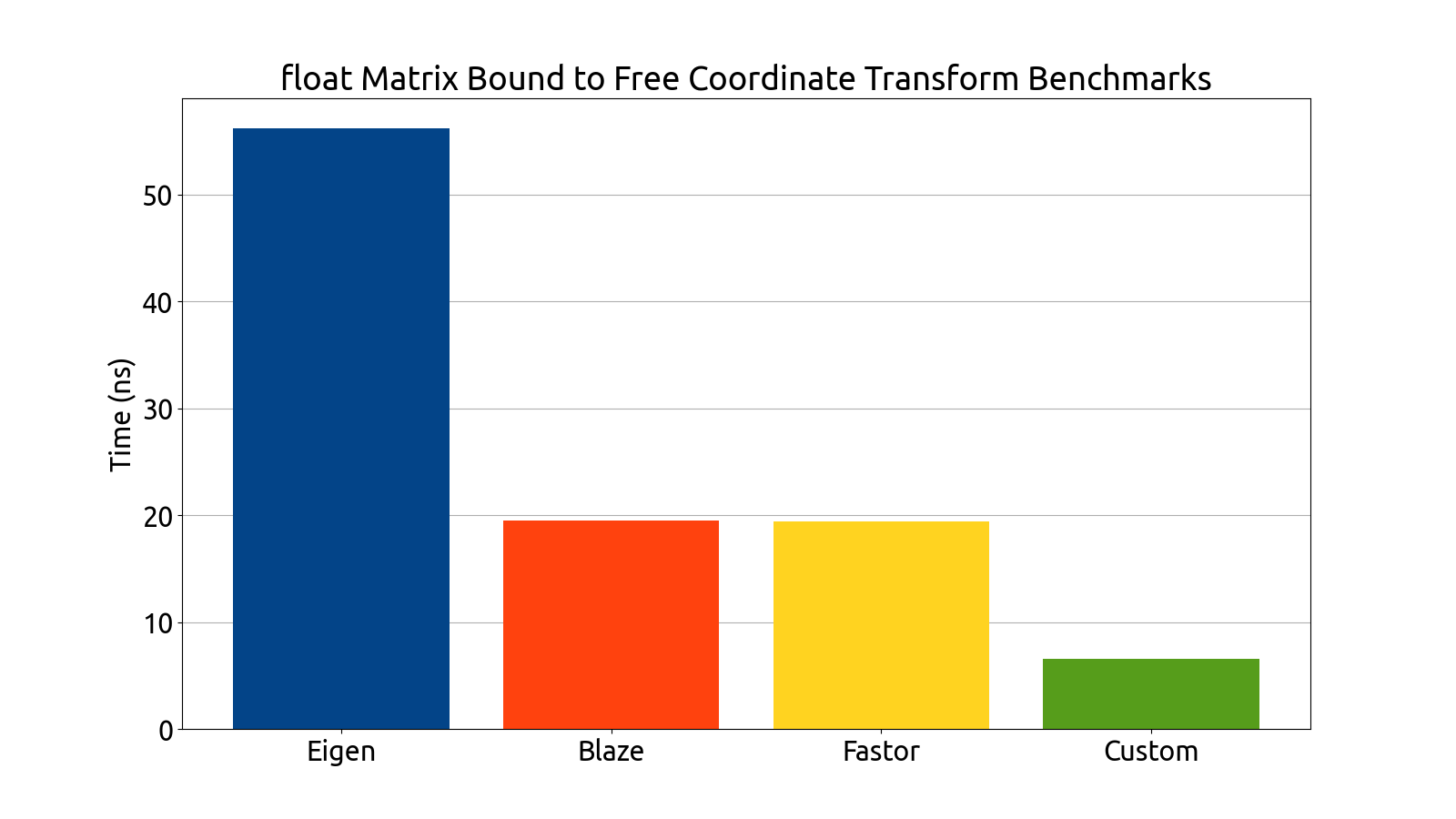
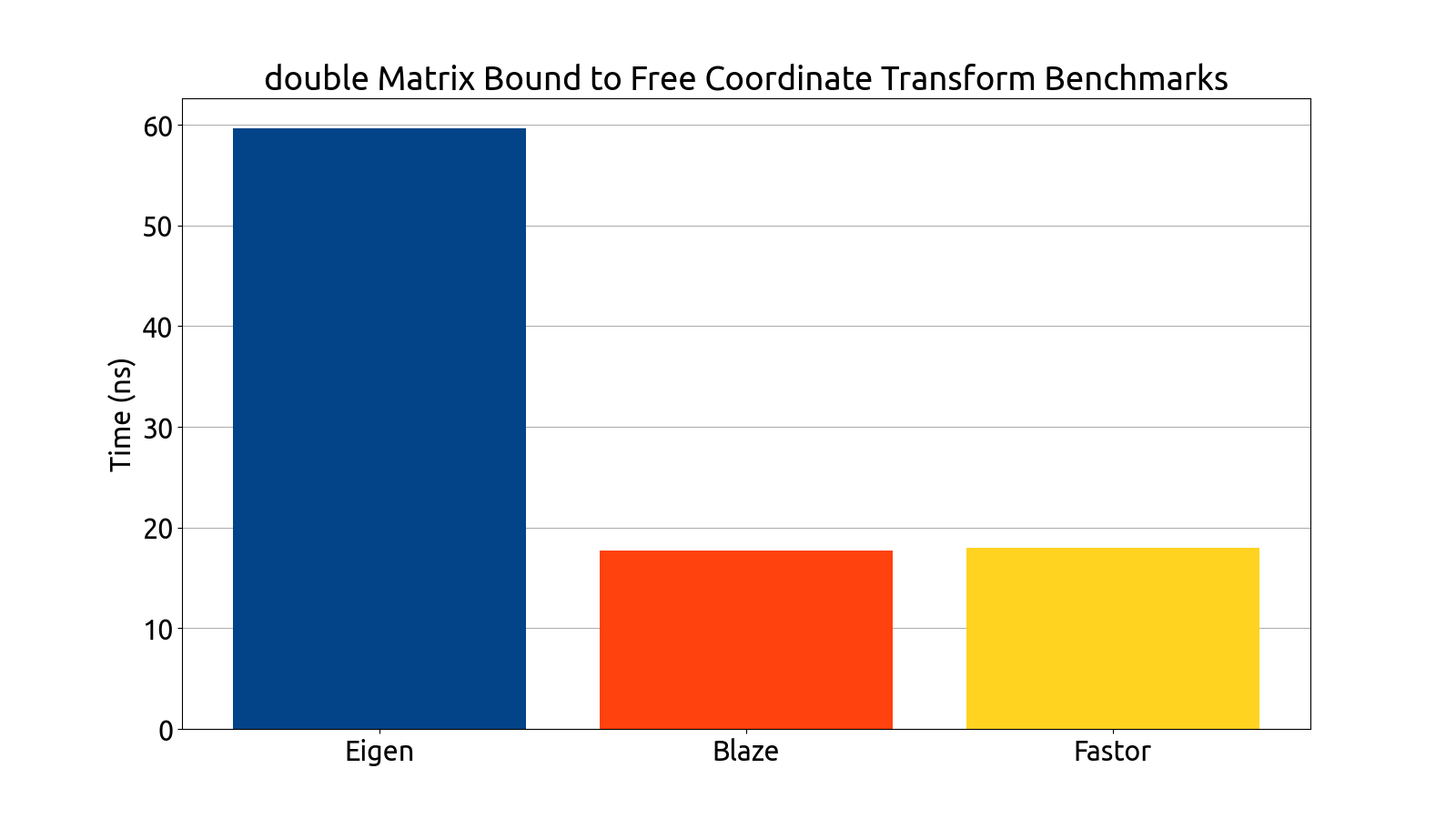
Note that the bar graphs for the custom backend and double matrices do not exist for the 6×6 and 8×8 dimensions. This is an intentional and recurring theme: The custom backend has a size limitation which prevents it from being usable for 6×6 and 8×8 matrices without the AVX512 instruction set, which my processor (at the time of writing) does not support. For this reason, the custom 6×6 and 8×8 data is missing from all of my benchmark plots.
After gathering the data, my mentors and I analyzed the performance of each backend. After a deep look into the assembly generated by each backend, as well as a look at the performance each library brought to the table, we decided to use Fastor because it was consistently first or second in all the benchmarks we threw at it, and its assembly generation was the cleanest (i.e. free of cruft and the pointless register shuffling that plagued a few of the other backends).
That’s it for the status report of the work so far! The next steps for me and my GSoC project are to
- integrate Fastor into
algebra-plugins, and - write the frontend for it so that we can see Fastor in action in a more realistic setting.
To that end, I already integrated Fastor to the repository in PR #77, and am currently working on writing the frontend.
Leave a comment