GSoC — The Details of My Project
In this post, I will discuss what exactly my work is and its relation to the ACTS project.
Project Description
The original project description was:
We propose the development of a linear algebra plugin for ACTS, which makes use of explicit vectorization.
- Port a similar existing library implementation (fast5x5/xsimd) to a suitable library backend (can be decided upon together with the student).
- Adapt the implementation to the linear algebra operations needed in the ACTS numerical integration for particle propagation.
- Validate the approach and its performance and possibly optimize the performance further.
- Given enough time, find a way to make the implementation available to ACTS as a compute backend and run it in ACTS example code.
The project, as described on the CERN-HSF webpage, can be found here.
What is Vectorization?
All matrix math libraries use something called SIMD (short for Single Instruction, Multiple Data) to achieve a speed-up compared to a naïve implementation.
Let’s take the example of adding two 4-dimensional vectors together. The naïve way of doing it is to take one element from each vector, add it, and then store the result in the result vector. This takes 4 add instructions to complete. However, with a SIMD ISA (Instruction Set Architecture) all one needs to do is load the 4 elements of each vector into a SIMD register, add them, and store the result in a result vector. This takes just 1 add instruction to complete.
In this simple example, using SIMD instructions gave us an approximately 4× speed-up.
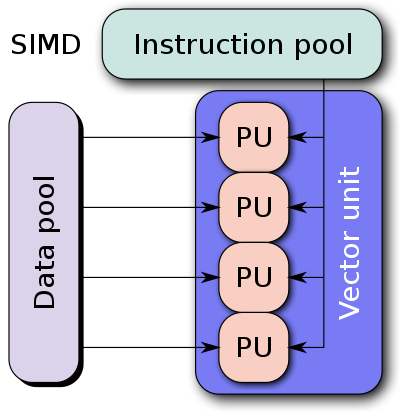
However, it is not as simple as that. There are many SIMD ISAs, for example SSE, SSE2, SSE3, SSSE3 (note the one extra “S”!), SSE4, AVX, AVX2, AVX512, and more.
A given CPU may not support all of these ISAs. (For example, the processor I have at the time of writing, an i7-12700H does not support AVX512.)
Code that is optimized for one ISA may not necessarily be optimized for other ISAs. For this reason, most people prefer to outsource their SIMD code to an external library dedicated to figuring out these headaches. Many such libraries exist, and they broadly fall into two categories:
The first type simply exposes SIMD intrinsics to the user in an uniform way: The add instruction in SSE2 is called _mm_add_ps, whereas it is called _mm256_add_ps in AVX. (The add_ps here stands for “add packed scalars.) Writing code which behaves well with multiple SIMD ISAs would involve a ridiculous amount of code repetition, which is what these types of libraries aim to minimize. xsimd is a great example of such a library.
The second type goes one step further and offers fully vectorized types such as a 4-element float/double array which will use a vectorized add instruction to add all the elements at once. A good example of such a library is Vc.
Alternate Project Description
The aforementioned project description might be a little terse for some. This is the way I like to explain it to others:
CERN generates a lot of data from its LHC experiments. For this reason, they have a lot of software projects which are data analysis oriented. The ACTS project is one such software package which does track reconstruction.
ACTS uses matrix operations in many places, such as for doing track reconstruction and covariance transport. However, the people who work on the ACTS project noticed that the matrix libraries they were using were quite slow for small dimensions (like 4×4, 6×6, 6×8, and 8×8). Upon further investigation, it turned out that popular matrix libraries like Eigen and SMatrix are not well-optimized for these dimensions. For example, I found during my benchmarking investigations that Eigen is about 6.5 times slower at inverting a double 8×8 matrix than a better optimized library like Fastor.
Some time ago, an alternate implementation of 4×4 matrices and the related operations were written using a library called Vc, and it performed quite well in benchmarks at the time.
My work is to continue this work and write implementations for all these desired dimensions, so that the ACTS project’s routines run faster.
I will go more into the details of the work and what we have accomplished so far in the next blog post. For now, I will discuss a bit about our weekly meeting schedule, and what it is like to work with my mentors.
My Project Proposal
My proposal can be found here. The only change I suggested was to use xsimd instead of Vc, because the latter is not in active development anymore.
Where Would The Work Go?
The math code in the ACTS Project proper is inextricably linked with the track-fitting code, so it would be a lot of work to change that.
However, in the ACTS project family, there are two research repositories: detray and traccc. These two repositories were started a couple of years after the original ACTS Project, so their approach to the math code is also slightly different. Both of these projects use another ACTS family project called algebra-plugins as a layer of abstraction over the different functions that matrix libraries like Eigen and SMatrix provide. This allows the developers of these research repositories to easily switch between math backends and test them out.
My work involves fleshing out the Vc portion of algebra-plugins, and adding all the functions which are present in the other math backends but not in the Vc stuff yet.
My work involves out the Vc portion of algebra-plugins, and adding all the functions which are present in the other math backends but not in the Vc stuff yet.
Weekly Meeting Schedule
We usually meet on Mondays at 10:00 am CEST (1:30 pm IST). Sometimes, we meet on other days, if the day is a holiday in some country, or one of us has other commitments.
Mentors
I have the pleasure of working with 3 highly qualified mentors. I will write a bit about each person:
Joana Niermann
She is currently a PhD student in the University of Göttingen.
She was the first person I contacted, about my interest in working on this project for GSoC, so we have been corresponding since late March of this year. She is a developer in the detray R&D project. In our weekly meets, she regularly helps us set the direction for the week, and also helps with gathering more data by running the benchmarks I have written on other machines.
Hadrien Grasland
Hadrien is a software engineer who works for the Centre National de la Recherche Scientifique (CNRS).
His knowledge of the nitty-gritty details of computer architecture and SIMD instruction sets is unparalleled. I am highly grateful to work with him, and I have learned a lot by working on this project with him, and discussing the assembly outputs of the different benchmarks I have written.
In the early stages of the project, he was quite supportive of me adding other matrix library backends to our benchmarks, and seeing how they perform in comparison with Eigen and Fast 5×5.
Paul Gessinger-Befurt
He is the person who knows the most about ACTS project out of all three mentors. When we have any questions about anything related to the ACTS project, he is the person who helps us out.
That’s all for this blog post! In the next one, I will discuss our results so far in detail, and what we plan on doing next.
Leave a comment